Welcome to klib’s documentation!¶
Getting started¶
How to install and contribute.
Documentation and Examples¶
User guides, examples and best practices for the functions contained in klib.
Modules¶
Detailed information on all the functions and classes and how to use them. This includes the input types and shapes for all mandatory and optional parameters.
Changes, Updates and known Issues¶
Changes, Updates and known Issues.
About klib¶
Contact information and links.
klib¶



klib is a Python library for importing, cleaning, analyzing and preprocessing data. Future versions will include model creation and optimization to provide an end-to-end solution.
Installation¶
Use the package manager pip to install klib.

pip install klib
pip install --upgrade klib
Alternatively, to install this package with conda run:

conda install -c conda-forge klib
Usage¶
import klib
klib.describe # functions for visualizing datasets
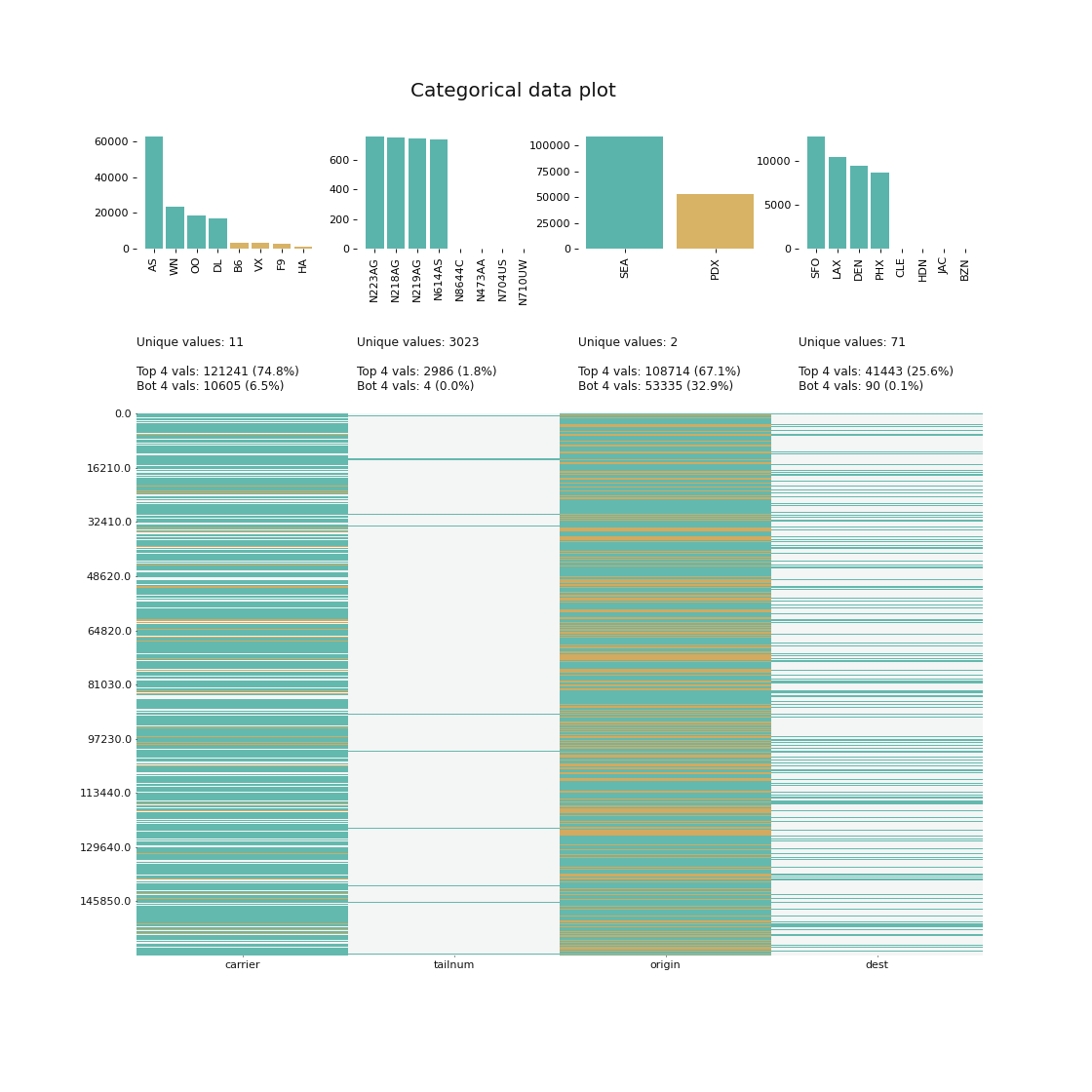
- klib.cat_plot() # returns a visualization of the number and frequency of categorical features.
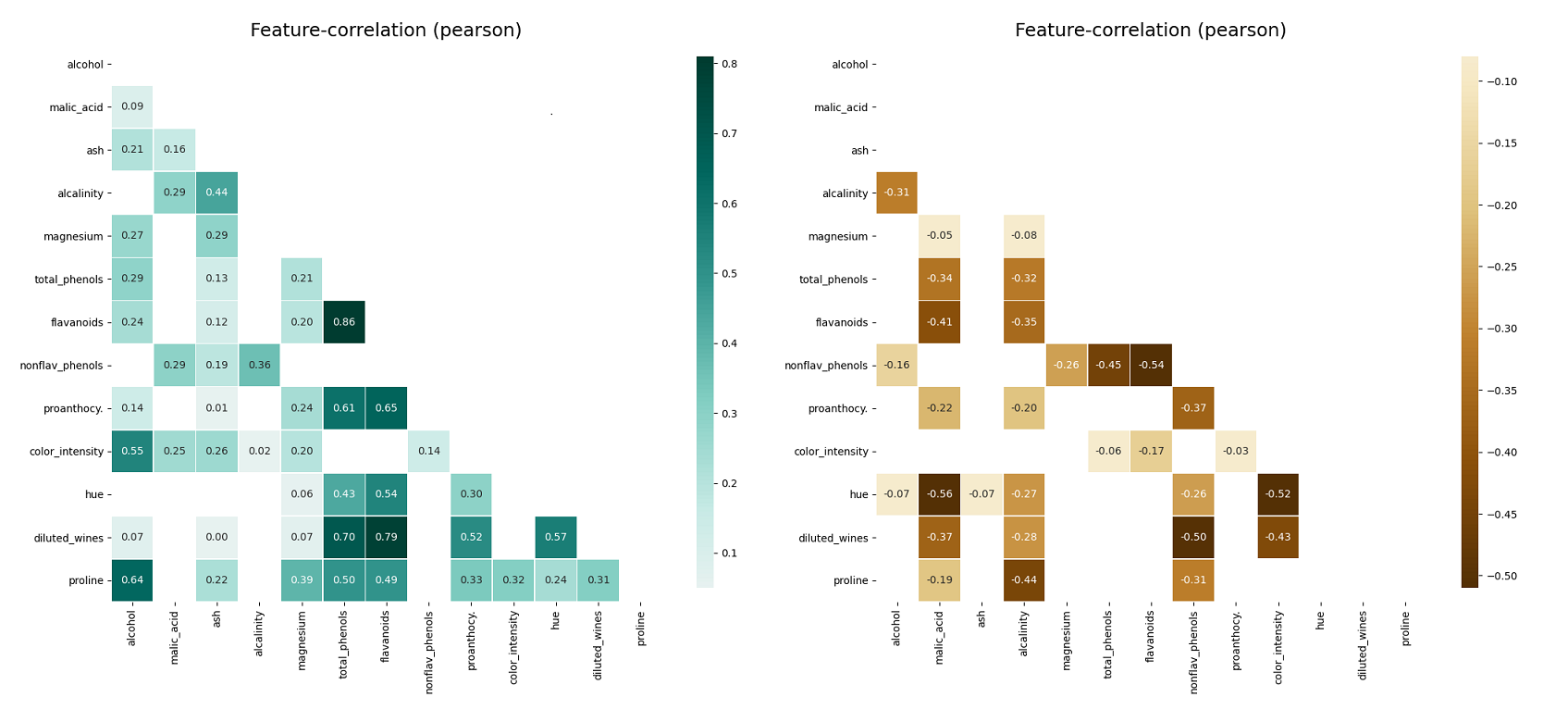
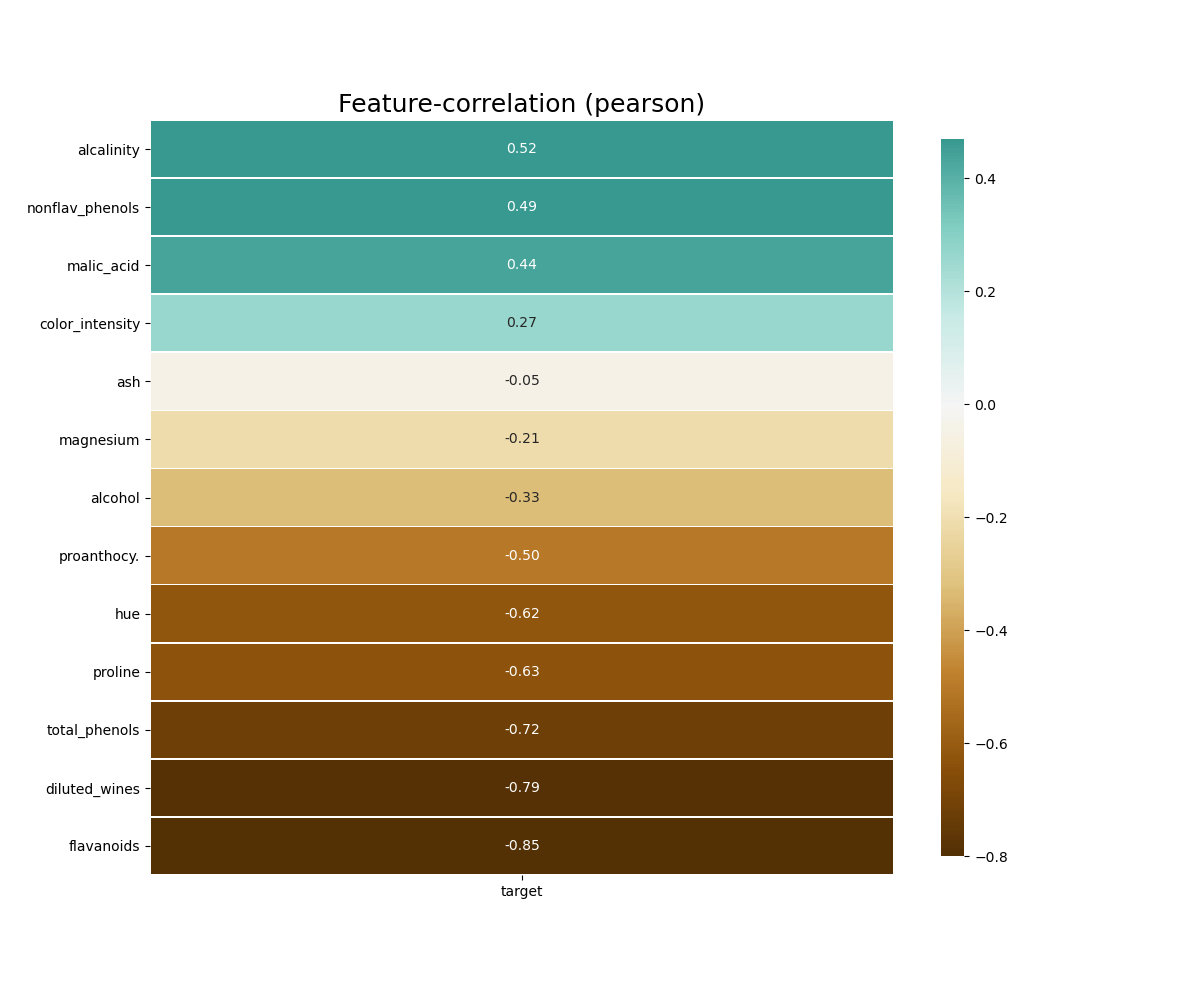
- klib.corr_mat() # returns a color-encoded correlation matrix
- klib.corr_plot() # returns a color-encoded heatmap, ideal for correlations
- klib.dist_plot() # returns a distribution plot for every numeric feature
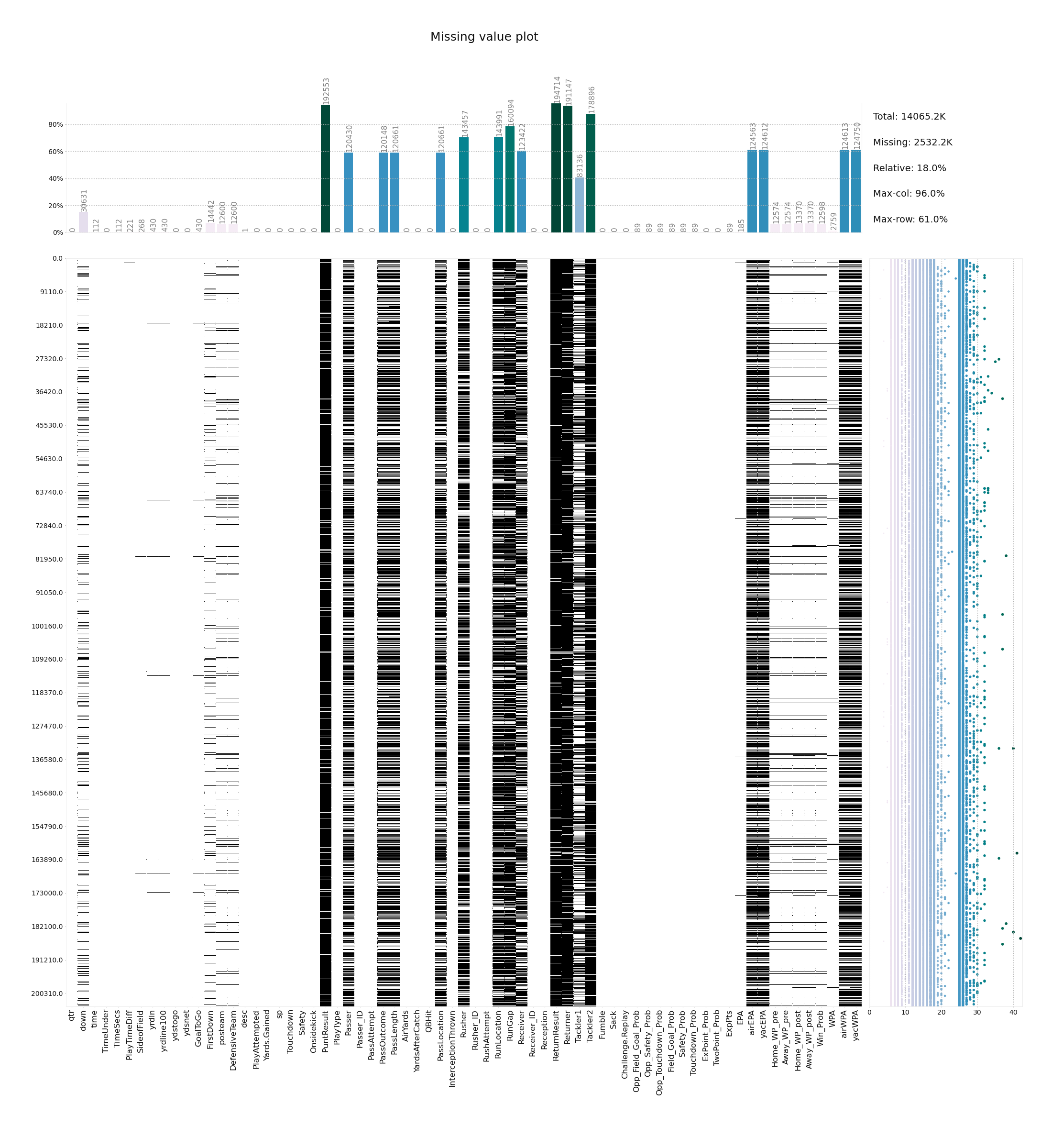
- klib.missingval_plot() # returns a figure containing information about missing values
klib.clean # functions for cleaning datasets
- klib.data_cleaning() # performs datacleaning (drop duplicates & empty rows/columns, adjust dtypes,...) on a dataset
- klib.convert_datatypes() # converts existing to more efficient dtypes, also called inside ".data_cleaning()"
- klib.drop_missing() # drops missing values, also called in ".data_cleaning()"
- klib.mv_col_handling() # drops features with a high ratio of missing values based on their informational content
- klib.pool_duplicate_subsets() # pools a subset of columns based on duplicate values with minimal loss of information
klib.preprocess # functions for data preprocessing (feature selection, scaling, ...)
- klib.train_dev_test_split() # splits a dataset and a label into train, optionally dev and test sets
- klib.feature_selection_pipe() # provides common operations for feature selection
- klib.num_pipe() # provides common operations for preprocessing of numerical data
- klib.cat_pipe() # provides common operations for preprocessing of categorical data
- klib.preprocess.ColumnSelector() # selects numerical or categorical columns, ideal for a Feature Union or Pipeline
- klib.preprocess.PipeInfo() # prints out the shape of the data at the specified step of a Pipeline
Examples¶
Find all available examples as well as applications of the functions in klib.clean() with detailed descriptions here.
klib.missingval_plot(df) # default representation of missing values in a DataFrame, plenty of settings are available
klib.corr_plot(df, split='pos') # displaying only positive correlations, other settings include threshold, cmap...
klib.corr_plot(df, split='neg') # displaying only negative correlations
klib.corr_plot(df, target='wine') # default representation of correlations with the feature column
klib.dist_plot(df) # default representation of a distribution plot, other settings include fill_range, histogram, ...

klib.cat_plot(data, top=4, bottom=4) # representation of the 4 most & least common values in each categorical column
Further examples, as well as applications of the functions in klib.clean() can be found here.
Contributing¶
Pull requests and ideas, especially for further functions are welcome. For major changes or feedback, please open an issue first to discuss what you would like to change.